Overview
Most quantization evaluations report whole-benchmark scores — "Llama 3.1 8B at Q4 retains 96% of FP16's MMLU" — and stop there. That's a leaderboard number. A PM choosing what precision to ship for a feature needs the next layer of question: for which workloads is that 4% loss concentrated, and which workloads pass through unaffected?
This study runs three quantization arms (FP16, Q8_0, Q4_K_M) of Llama 3.1 8B Instruct across two contrasting tasks — MMLU and CoNLL-2003 NER — under a paired design, with the same items, prompts, and seed across every arm. The deliverable is a decision framework, not a leaderboard.
Problem framing
Three observations shape the design:
- Quantization is a real production decision, and most teams pick by feel. Ship at FP16 and pay for the GPU memory; ship at Q4 and absorb some quality loss for cheaper, faster inference. The cost side is concrete and easy to measure. The quality side is where the hand-waving happens.
- Published evaluations are leaderboards, not decision frameworks. "Q4 retains 96% of FP16's MMLU" is one number per arm and doesn't separate the workloads where the loss is concentrated from the workloads where it isn't.
- Independent-sample comparisons throw away variance reduction the design is sitting on. Same items run through every arm means the per-example difference is paired data — exploit that with paired CIs and you get materially tighter effects at the same sample size.
Design
Three arms. FP16 (control), Q8_0, Q4_K_M. All pulled from Ollama: llama3.1:8b-instruct-{fp16|q8_0|q4_K_M}.
Two tasks chosen for contrast.
- MMLU — knowledge/reasoning, four-way multiple choice. Stratified subset of 500 questions across 10 subjects (STEM, humanities, professional). Mechanically scored: parse the first A–D character from the output.
- CoNLL-2003 NER — structured information extraction. 300 sentences from the test split, model returns a JSON array of
(entity, type)pairs, scored by exact span match with type agreement. Reported two ways: corpus micro-F1 (the canonical CoNLL/conlleval metric — pool TP/FP/FN, then F1) as the headline, and per-sentence macro-F1 (mean of per-example F1) as a brittleness view. The gap between them turns out to localize the failure mode.
The contrast is the point. MMLU is closer to "did the model retain the knowledge"; NER is closer to "did the model produce the structured artifact the downstream system expects." Different failure modes surface in different tasks.
Paired design with round-robin scheduling. Every example scored across all three arms before moving on. Warmups for all three arms precede the timed loop, so cold-start latency doesn't bias whichever arm runs first. Without round-robin, an hour of one arm's runtime collects thermal and macOS-daemon-load drift that distorts the tok/sec column.
Deterministic sampling. Temperature 0, fixed seed (42), identical prompts and system messages, max-tokens task-appropriate. Held constant across arms.
Headline result
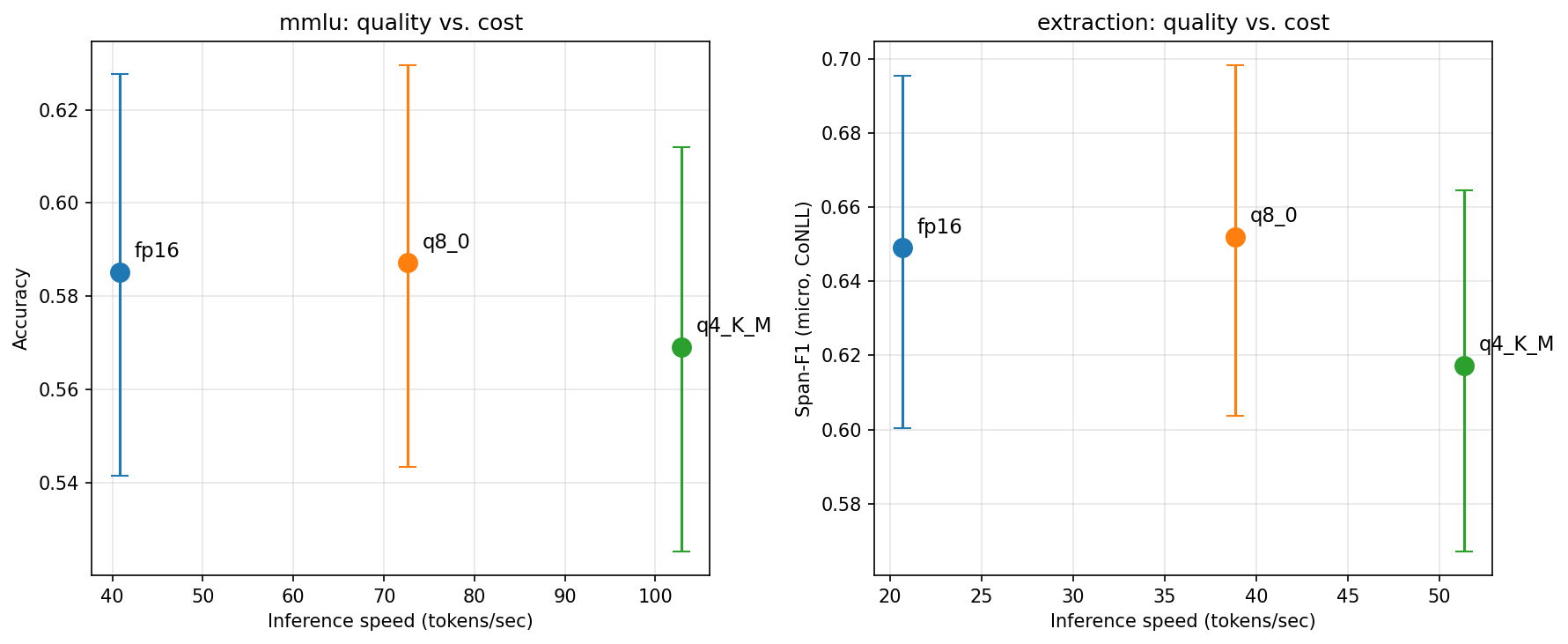
Q8_0 is practically equivalent to FP16 — a positive claim, not just "not significant." Against a specified ±1pp practical-equivalence margin, a TOST clears equivalence on MMLU accuracy (Δ = −0.2pp, p_TOST = 0.019) and on NER per-sentence F1 (Δ = +0.0003, p_TOST = 0.002), and the canonical NER micro-F1 95% CI ([−0.9, +0.2]pp) sits entirely inside ±1pp. All this at ~1.8× the throughput and half the memory footprint.
Q4_K_M loses 3.2pp on canonical corpus micro-F1 (95% CI: [0.7, 5.7pp]; Holm-adjusted p = 0.032), and 5.0pp on per-sentence macro-F1 (CI: [2.1, 8.1pp]; p = 0.003) — significant under both estimands, so the degradation is robust to metric choice. You buy that for ~40% more throughput and an ~3× smaller footprint. The MMLU regression (1.6pp) does not reach significance.
The failure mode
The gap between the two F1 metrics is the tell. Q4's NER hit is over-extraction, not missed entities — decomposing the corpus counts, it loses 4.1pp of precision but only 0.9pp of recall versus FP16. It invents entities rather than dropping them.
That over-extraction concentrates on entity-free sentences. Of the 72 sentences (24% of the corpus) whose correct answer is the empty set, FP16 and Q8_0 correctly return [] ~60% of the time; Q4 only 37.5% — it hallucinates a spurious entity on the rest. This is exactly why macro-F1 (5.0pp) exceeds micro-F1 (3.2pp): per-sentence averaging gives each empty sentence full weight, so one hallucination tanks the whole sentence to zero, while corpus micro-F1 dilutes the same spurious entities across the entity pool.
It matters downstream because it's structurally invisible: Q4 has the highest JSON parse rate of the three arms (99.7%), so schema validation passes — the content is just wrong. Whatever checks the entities has to check the entities; there's no cheaper proxy.
The published intuition that "Q4 is fine for pattern-matching, hurts on reasoning" doesn't hold here. NER is a structured pattern-extraction task, and it's where Q4 visibly degrades; MMLU (more reasoning-heavy) shows a numerically smaller Q4 regression that doesn't reach significance. In this run the degradation reads as a precision/calibration failure — Q4 over-commits to entities, especially where there are none — rather than a reasoning-difficulty one. That's an observed pattern in this data, not a claim about the model's internals.
Statistical methodology
The paired design earns its keep in the analysis:
- Per-arm CIs. Wilson 95% interval for MMLU accuracy; bootstrap CI on the canonical corpus micro-F1 for NER (resample examples, re-pool TP/FP/FN), with per-sentence macro-F1 reported alongside.
- Pairwise differences. Paired bootstrap on per-example deltas (macro / accuracy) and on the pooled micro-F1 difference. Same items in both arms means the difference is a real number whose variance is reduced by the pairing.
- p-values. McNemar's test for binary outcomes (exact binomial for ≤25 discordants; Yates continuity-corrected χ² otherwise); paired bootstrap centered under H0 for the F1 estimands.
- Equivalence ≠ non-significance. "Q8_0 ≈ FP16" is a TOST (two one-sided tests) against a specified ±1pp practical-equivalence margin — equivalently, the 90% CI lying inside ±0.01. A non-significant difference test would not establish equivalence; the TOST does.
- Multiple-comparison correction. Holm-Bonferroni applied per task across the three pairwise tests. Per-task framing matches the reader's per-section interpretation; Holm is uniformly more powerful than Bonferroni and doesn't require the BH PRDS assumption (which paired tests within a task violate).
- Cluster-bootstrap on subjects for the MMLU overall CI. Examples within an MMLU subject are correlated — questions in
professional_medicinelook like otherprofessional_medicinequestions. The iid bootstrap underestimates variance; cluster-bootstrap resamples subject IDs with replacement and pulls all examples from chosen subjects, giving the correct width. - Provenance. A committed
experiment_manifest.jsonrecords the per-arm weight-blob SHA256s, modelfiles, Ollama version, and host — so "only quantization varied across arms" is backed by recorded artifact identity rather than assumed.
Power. At n=499 aligned per arm on MMLU, the design detects ≥3.8pp accuracy differences at 80% power, α=0.05 (paired diff SD = 0.30 observed). At n=300 per arm on NER, ≥4.3pp per-sentence F1 (paired diff SD = 0.27 observed). Both post-hoc verified on the actual data.
Where the effect concentrates
The Q4-vs-FP16 gap on MMLU is concentrated in miscellaneous (−6.0pp) and professional_medicine (−6.0pp), with smaller regressions in moral_scenarios, abstract_algebra, and machine_learning (each −4.0pp). Several subjects move the other way — professional_law (+4.0pp), college_computer_science (+2.0pp), high_school_us_history (+2.0pp) — within the noise band for n=50/subject.
None of the per-subject pairwise differences survives Holm correction within the per-subject family of three tests. This is suggestive heterogeneity worth flagging, not replicable evidence of subject-specific quantization sensitivity. A properly powered subject-level study would need ~3× the per-subject sample size. The pattern is consistent with the published intuition that quantization hits broad-knowledge recall harder than narrow reasoning, but the data here can only suggest it.
A decision framework
What a PM actually needs from a study like this:
Pick Q8_0 — the default.
- Practically equivalent to FP16 on both tasks (TOST, ±1pp), at ~1.8× throughput. The strongest evidence in the study is for Q8_0 ≡ FP16.
- Right call when a single model serves heterogeneous workloads.
- Right call when reasoning depth matters (multi-step, legal, medical) — MMLU shows Q8 holds.
Pick Q4_K_M only when:
- Throughput is the binding constraint and a measurable F1 hit on structured extraction is acceptable downstream (human review, retry logic, low-stakes outputs).
- Memory is the binding constraint: Q4_K_M's ~5 GB footprint vs FP16's ~16 GB matters on memory-limited machines (laptops, edge, multi-tenant serving).
Avoid Q4_K_M for structured information extraction. The NER gap is significant under both F1 estimands (3.2pp micro / 5.0pp macro), and it comes from over-extraction — Q4 emits well-formed JSON that adds spurious entities, harder to catch downstream than malformed output: schema validation passes, the content is wrong.
Stay at FP16 when:
- Accuracy is the binding constraint (regulated outputs, safety-critical, eval ground truth).
- The throughput delta from Q8 (~1.8×) doesn't move unit economics — inference cost isn't the constraint.
Reflections
- The single most consequential design choice was pairing. Same items, prompts, and seed across all three arms means the per-example difference is a real number whose variance is reduced by the pairing. Published Q4 evaluations that report unpaired benchmark numbers throw away the variance reduction the design hands them for free. Pairing is what let the NER effect clear significance under the canonical metric (3.2pp micro-F1, p_adj=0.032) at n=300.
- Round-robin scheduling matters more than it looks. The first draft of the harness ran arms sequentially (all of FP16, then all of Q8, then all of Q4). A senior review pass surfaced the failure mode: thermal drift and macOS daemon load on a laptop are real, and an hour of one arm's runtime collects enough drift to distort the tok/sec column by single-digit percentage points. Round-robin interleaves arms per example; the throughput numbers in the writeup are the cleaner ones.
- Multiple-comparison correction is where rigor pays. Three pairwise tests per task, two tasks — six tests total. Without correction, one of the marginal MMLU pairs would have been written up as suggestive. With Holm, it's correctly not significant. The corrected p-values are the ones in the README; the uncorrected ones aren't shown.
- The failure mode is the lede, not the headline number. "Q4 loses 3.2pp on NER" is the number. "Q4 over-extracts — it hallucinates entities on entity-free sentences, so schema validation downstream won't catch it" is the finding. The second is what changes how a team using Q4 should think about their validation pipeline. Putting it in the TL;DR was the right call.
- A second senior review caught a real metric error — and fixing it made the result stronger, not weaker. I had labeled the NER score "canonical CoNLL metric," but the code computed per-sentence (macro) F1; the canonical conlleval metric is corpus micro-F1. Recomputed from the committed outputs, the Q4 drop is 3.2pp micro (not 5.0pp), still significant — and reporting both metrics is what surfaced the actual mechanism: the macro/micro gap is the over-extraction-on-empty-sentences signal. I also turned "statistically indistinguishable" into a real TOST equivalence claim, added a provenance manifest (model digests) to back the causal framing, and verified one flagged "bug" was a non-issue (the MMLU parser misfire would have corrupted the numbers — checked all 1,500 outputs first). Every corrected number was recomputed from the committed data, with a CI job that now re-derives the summary so the writeup can't silently drift from the evidence.
Closing observation
The unit of value isn't the benchmark score. The unit of value is the decision framework with specific findings tied to specific pick-conditions. A PM reading the TL;DR can pick Q8_0 confidently for most workloads, knows the one workload class to avoid Q4 on, and has a concrete description of how Q4 fails when it does. That's a more useful artifact than a four-decimal benchmark table — and it's the format the work was actually trying to produce.